
티스토리 뷰
chapter07. 스토어드 프로시저
07-1. 스토어드 프로시저 사용 방법
sql은 데이터베이스에서 사용되는 언어이다.
sql을 사용 시 다른 프로그래밍 언어의 기능이 필요할 때가 있다.
그럴 경우 mysql의 스토어드 프로시저를 사용하는데 스토어드 프로시저는 sql에 프로그래밍 기능을 추가해서 일반 프로그래밍 언어와 비슷한 효과를 낸다.
스토어드 프로시저 기본
스토어드 프로시저의 개념과 형식
스토어드 프로시저(저장 프로시저)란 mysql에서 제공하는 프로그래밍 기능이다.
스토어드 프로시저는 쿼리 문의 집합으로 볼 수 있는데 이때 집합이라는 말은 단위작업을 말한다.
(단위작업이란 예를 들어 게시글을 불러올떄 select 후 insert하여 게시글을 db에서 불러 오는데 이러한 과정을 보고 단위 작업, 혹은 트랜잭션이라고 한다.)
delimiter $$
create procedure 스토어드_프로시저_이름(in 또는 out 매개변수)
begin
sql 프로그래밍 코드
end $$
delimiter ;
* delimiter은 '구분자'라는 의미로 mysql에서 스토어드 프로시저의 끝을 표기한다.
sql의 끝과 헷갈릴 수 있도록 delimiter을 표기하여 구분해준다.
* create porcedure은 스토어드 프로시저를 만든 것이며 실행(호출)한 것은 아니다. (프로시저 만드는 명령어)
* 실행은 call을 사용하여 호출한다.
call 스토어드_프로시저_이름();
스토어드 프로시저의 생성
use market_db;
drop procedure if exists user_proc;
delimiter $$
create procedure user_proc()
begin
select * fom member;
end $$
delimiter ;
call user_proc();
1. use를 사용하여 사용할 db를 지정한다.
2. 기존에 user_proc라는 이름의 스토어드 프로시저가 있다면 삭제하라는 명령어이다.
3. 스토어드 프로시저를 만드는 구문이며 이름은 user_proc로 지정했다.
4. 스토어드 프로시저 내용이다. member 테이블을 조회한다.
5. user_proc()이름의 스토어드 프로시저를 호출했다.
스토어드 프로시저의 삭제
user_proc의 내용을 삭제하려면 drop procedure를 사용한다.
drop procedure user_proc;
스토어드 프로시저 실습
매개변수의 사용
스토어드 프로시저에서는 실행 시 입력 매개변수를 지정할 수 있다.
입력 매개변수를 지정하는 형식
in 입력_매개변수_이름 데이터_형식
입력 매개변수가 있는 스토어드 프로시저를 실행하는 형식
call 프로시저_이름(전달_값);
입력 매개변수뿐만 아니라 출력 매개변수를 통해 얻을 수도 있다.
출력 매개변수의 형식
출력 매개변수에 값을 대입하기 위해서는 select ~ into 문을 사용한다.
out 출력_매개변수_이름 데이터_형식
출력 매개변수가 있는 스토어드 프로시저를 실행하는 형식
call 프로시저_이름(@변수명);
select @변수명;
입력 매개변수의 활용
프로시저의 이름 뒤에 매개변수를 입력하기 위해 in을 사용하여 매개변수 이름과 타입을 작성해주었다.
그리고 where 조건절에 대입하기 위해 변수를 작성해주었다.
입력매개변수를 실행하기 위해 call user_proc1('에이핑크'); 를 실행하여 에이핑크 일때의 값을 출력했다.
use market_db;
drop procedure if exists user_proc1;
delimiter $$
create procedure user_proc1(in username varchar(10))
begin
select * from member where mem_name = username;
end $$
delimiter ;
call user_proc1('에이핑크');

입력 매개변수는 한개가 아닌 여러개도 작성이 가능하다.
아래의 쿼리문은 2개의 입력 매개변수가 있는 스토어드 프로시저이다.
두개의 매개변수를 받고 매개변수보다 큰 값들을 가진 데이터를 출력했다.
drop procedure if exists user_proc2;
delimiter $$
create procedure user_proc2(in usernumber int, in userheight int)
begin
select * from member where mem_number > usernumber and height > userheight;
end $$
delimiter ;
call user_proc2(6,165);
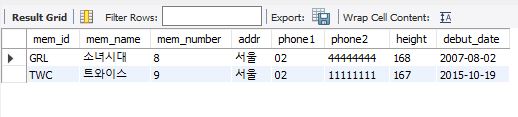
출력 매개변수의 활용
출력 매개변수가 있는 스토어드 프로시저를 생성했다.
매개변수를 작성하는 괄호 안에 out을 사용하여 출력 매개변수를 작성했다.
그 후 notable 테이블에 값을 삽입하도록 쿼리문을 작성해주었다.
데이터를 삽입한 후 max(id)를 into 명령어를 사용해 outvalue변수에 담았다.
drop procedure if exists user_proc3;
delimiter $$
create procedure user_proc3(in txtvalue char(10), out outvalue int)
begin
insert into notable values(null,txtvalue);
select max(id) into outvalue from notable;
end $$
delimiter ;
notable이 정보를 확인해보았다.
desc notable;
notable 테이블을 생성한적 없기 때문에 오류코드가 생성된다.
Error Code: 1146. Table 'market_db.notable' doesn't exist
notable 테이블을 생성하여 call user_proc3;명령어로 프로시저를 호출했다.
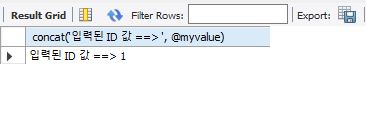
출력 매개변수에 @변수명 형태로 변수를 전달해 그 변수에 결과가 저장된다.
그 후 select를 통해 출력해주었다.
create table if not exists notable(id int auto_increment primary key, txt char(10));
call user_proc3('테스트1', @myvalue);
select concat('입력된 ID 값 ==> ', @myvalue);
sql 프로그래밍의 활용
스토어드 프로시저 안에 sql 프로그래밍을 활용했다. 또한 if ~ else 문을 사용했다.
데뷔 연도에 따라 메세지를 출력하는 스토어드 프로시저를 작성했다.
drop procedure if exists ifelse_proc;
delimiter $$
create procedure ifelse_proc(in memname varchar(10))
begin
declare debutyear int;
select year(debut_date) into debutyear from member where mem_name = memname;
if(debutyear >= 2015) then select '신인 가수네요. 화이팅 하세요.' as '메시지';
else select '고참 가수네요. 그동안 수고하셨어요.' as '메시지';
end if;
end $$
delimiter ;
call ifelse_proc('오마이걸');
ifelse_proc는 입력매개변수를 가진다.
call ifelse_proc('오마이걸')이므로 매개변수가 오마이걸이다.
mem_name='오마이걸'인 값들을 조회한다.
declare로 변수를 생성하고 sleect 문을 사용해 데뷔일자를 조회하도록 했다. 조회한 데뷔 일자는 into 뒤에 있는 debutyear 변수에 저장한다.
변수에 저장된 값으로 2015와 비교해 메시지를 출력한다.

* 날짜와 관련된 mysql 함수
- select year(curdate()) : 연
- month(curdate()) : 월
- day(curdate()) : 일
07-2. 스토어드 함수와 커서
스토어드 함수는 mysql에서 제공하는 내장 함수 외에 직접 함수는 만드는 기능을 제공한다.
스토어드 함수는 스토어드 프로시저와 비슷해보이지만 returns 예약어를 통해 하나의 값을 반환해야 한다.
커서는 스토어드 프로시저 안에서 한 행씩 처리할 때 사용하는 프로그래밍 방식이다.
(자바에서 hasnext()와 비슷함)
스토어드 함수의 개념과 형식
mysql은 다양한 함수를 제공한다. 하지만 없는 함수가 존재할 수도 있는데 이때 직접 함수를 만들어서 사용하는 것을 스토어드 함수라고 한다.
delimiter $$
create function 스토어드_함수_이름(매개변수)
returns 반환형식
begin
프로그래밍 코딩
return 반환값;
end $$
delimter ;
select 스토어드_함수_이름();
스토어드 함수와 스토어드 프로시저의 차이점
* 스토어드 함수의 형식이다. 스토어드 프로시저와 비슷해보이지만 몇가지 차이점이 있다.
* create procedure로 생성하지만 스토어드 함수에서는 create function을 사용하여 생성한다.
* returns문으로 반환할 값의 데이터 형식을 지정한다. 본문 안(begin ~ end)에서는 return문으로 하나의 값을 반환한다.
* 스토어드 함수의 매개변수는 모두 입력 매개변수이다. 출력 매개변수는 없다. 구별할 필요가 없으므로 in을 따로 붙이지 않는다.
* 스토어드 프로시저에서는 call로 호출했다. 하지만 스토어드 함수는 select 문 안에서 호출된다.
* 스토어드 프로시저 안에서는 select문을 사용할 수 있지만 스토어드 함수 안에서는 select 를 사용할 수 없다.
* 스토어드 프로시저는 여러 sql문이나 숫자 계산 등의 다양한 용도로 사용한다. 하지만 스토어드 함수는 어떤 계산을 통해 하나의 값을 반환하는데 사용된다. (용도에 따라 프로시저 사용할지 함수 사용할지 결정함 / 스토어드 함수는 계산 결과를 꼭 반환한다.)
스토어드 함수의 사용
스토어드 함수를 사용하기 위해서는 sql로 스토어드 함수 생성 권한을 허용해줘야한다.
한번만 실행하면 된다.
set global log_bin_trust_function_creators = 1;생성권환 true(=1)로 설정
숫자 2개의 합계를 계산하는 스토어드 함수이다.
set global log_bin_trust_function_creators = 1;
use market_db;
drop function if exists sumfunc;
delimiter $$
create function sumfunc(number1 int, number2 int)
returns int
begin
return number1 + number2;
end $$
delimiter ;
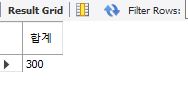
select sumfunc(100,200) as '합계';
returns로 데이터 반환형식을 지정했다.
그리고 return으로 데이터의 합계를 반환해주었다.
아래는 데뷔연도를 입력받아 활동 기간이 얼마나 되었는지 출력하는 함수이다.
returns로 데이터 반환타입을 지정하고 입력매개변수를 받았다.(in 생략)
또한 계산 값은 변수를 생성하여 변수에 담아 리턴했다.
drop function if exists calcyearfunc;
delimiter $$
create function calcyearfunc(dyear int)
returns int
begin
declare runyear int;
set runyear = year(curdate()) - dyear;
return runyear;
end $$
delimiter ;
select calcyearfunc(2010) as '활동 햇수';
함수의 반환 값을 select ~ into ~로 저장하여 사용할 수 있다.
아래는 select ~ into를 사용하여 변수에 반환값을 담아 맨 아래의 select문을 통해 변수 값을 빼 계산 값을 출력해주는 쿼리문을 작성했다.
select calcyearfunc(2007) into @debut2007;
select calcyearfunc(2013) into @debut2013;
select @debut2007 - @debut2013 as '2007과 2013차이';
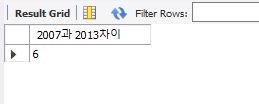
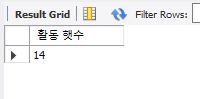
아래와 같이 회원 테이블의 모든 회원이 데뷔한지 몇년되었는지 조회할 수 있다.
YEAR()함수는 연도만 추출해주는데 debut_date에 저장되어 있는 데이터 중 연도만 추출하여 calcyearfunc함수의 입력매개변수로 넣어주어 활동기간을 계산하여 출력했다.
select mem_id, mem_name, calcyearfunc(year(debut_date)) as '활동 햇수' from member;
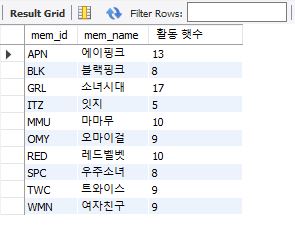
함수의 삭제
drop을 사용한다.
drop function calcyearfunc;
커서
커서는 테이블에서 한행씩 처리하기 위한 방식이다.
첫번째 행을 처리한 후 차례대로 한행씩 접근하여 마지막 행까지 값을 처리한다.
(resultset과 같다.)
커서의 단계별 실습
1. 사용할 변수 준비
회원의 평균 인원수를 계산하기 위한 함수를 작성하는 것이다.
그러므로 회원의 인원수, 전체 인원의 합계, 읽은 행의 수 총 3개의 변수를 생성하여 준비한다.
전체 인원 합계와 읽은 행의 수는 누적시켜야하기 때문에 default문을 사요해 0으로 설정했다.
declare memnumber int;
declare cnt int default 0;
declare totnumber int default 0;
행의 끝을 파악하기 위해 변수를 하나 더 생성했다.
처음 시작은 행의 끝이 아니므로 false로 초기화 했다.
declare endofrow boolean default false;
2. 커서 선언하기
커서를 선언했다.
커서는 차례대로 행을 읽는 것이므로 select문과 같은 역할을 한다.
회원 테이블을 조회하는 구문을 커서로 만들었다. 이때 커서의 이름은 membercursor이다.
declare membercursor cursor for select mem_number from member;
3. 반복 조건 선언
행을 무한으로 반복할수는 없다 반복하지 않게하기 위해 행의 끝을 파악하기 위해 생성한 변수 값을 true로 설정했다.
declare continue handler for not found set endofrow = true;
또한, declare continue handler라는 예약어를 사용했다.
이 예약어는 반복 조건을 준비하는 예약어이다.
for not found는 더 이상 행이 없을 때 이어지는 문장을 수행하도록 한다.
이 말은 즉 행이 끝나면 endofrow에 true를 대입한다는 말이다.
4. 커서 열기
앞에서 선언한 커서를 열어 실행해야한다.
open membercursor;
5. 행 반복하기
처음부터 끝까지 한 행씩 접근하여 코드를 반복하는 부분이다.
cursor_loop : LOOP ~ end LOOP cursor_loop; 사이의 코드를 반복한다.
cursor_loop : LOOP
fetch membercursor into memnumber;
if endofrow then leave cursor_loop;
end if;
set cnt = cnt +1;
set totnumber = totnumber + memnumber;
end LOOP cursor_loop;
위에서 leave는 반복할 이름을 빠져나가는 명령어이다.
자바에서의 break;와 같은 역할을 한다.
행의 끝까지 오면 endofrow가 true로 변경되고 반복하는 부분을 빠져나간다.
fetch는 반복부분에 넣는 것인데 한행씩 읽어오는 것이다.
커서를 선언할 때 인우너수 행을 조회했으므로 memnumber변수에는 각 회원의 인원수가 한번에 하나씩 저장된다.
그리고set부분에서 읽은 행의 수(cnt)를 하나씩 증가시키고 인원수도 totnumber에 계속 누적시킨다.
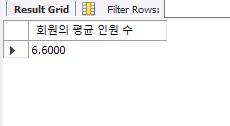
반복을 빠져나와 회원의 평균 인원수를 계산한다.
누적된 총 인원수를 읽은 행의 수로 나눈다.
select (totnumber/cnt) as '회원의 평균 인원 수';
6. 커서 닫기
모든 작업이 끝났으므로 커서를 닫는다.
close membercursor;
아래는 위의 커서의 통합 코드이다.
use market_db;
drop procedure if exists cursor_proc;
delimiter $$
create procedure cursor_proc()
begin
declare memnumber int;
declare cnt int default 0;
declare totnumber int default 0;
declare endofrow boolean default false;
declare membercursor cursor for select mem_number from member;
declare continue handler for not found set endofrow = true;
open membercursor;
cursor_loop : LOOP
fetch membercursor into memnumber;
if endofrow then leave cursor_loop;
end if;
set cnt = cnt +1;
set totnumber = totnumber + memnumber;
end LOOP cursor_loop;
select (totnumber/cnt) as '회원의 평균 인원 수';
close membercursor;
end $$
delimiter ;
call cursor_proc();
마지막에 cursor_proc()하여 호출해주어야 값을 출력할 수 있다.
07-3. 자동 실행되는 트리거
트리거
트리거는 테이블에서 DML문 (insert, update, delete)이 작동할 때 자동으로 실행되는 프로그래밍 기능이다.
트리거를 활용하여 데이터가 삭제될 때 데이터를 다른 곳에 자동으로 백업할 수 있다.
테이블에 미리 부착되는 프로그램 코드로스토어드 프로시저와 문법이 비슷하지만 call문으로 직접 실행할 수 없다.
앞서 말한 것과 같이 insert, update, delete 등의 이벤트가 발생할 경우에만 자동 실행된다.
또한, in, out 매개변수를 사용할 수 없다.
트리거를 사용하면 데이터에 오류가 발생되는 것을 막을 수 잇다. 이것을 데이터의 무결성이라고 부른다.
트리거 예시
테이블 생성
use market_db;
create table if not exists trigger_table (id int, txt varchar(10));
insert into trigger_table values(1, '레드벨벳');
insert into trigger_table values(2,'잇지');
insert into trigger_table values(3, '블랙핑크');
테이블에 트리거를 부착한다.
create trigger은 트리거를 생성하고 after delete on trigger_table 은 delete 이후에 실행하도록 설정 했다.
for each row 는 한줄씩 실행하라는 명령어이다.
begin ~ end 안의 코드는 트리거 실행시 작동되는 코드를 작성한다.
drop trigger if exists mytrigger;
delimiter $$
create trigger mytrigger after delete on trigger_table for each row
begin
set @msg = '가수 그룹이 삭제됨' ; -- 트리거 실행시 작동되는 코드
end $$
delimiter ;
delete를 실행했을때 트리거를 실행하도록 했기때문에 insert나 update 등 다른 쿼리문을 실행했을 때도 실행되는지 확인해보았다.
set @msg = '';
insert into trigger_table values(4,'마마무');
select @msg;
update trigger_table set txt = '블핑' where id = 3;
select @msg;
@msg 변수에 공백으로 초기값을 설정하고 insert를 한 후 변수를 조회한 결과 아무것도 나오지 않았다.
update 또한 같은 결과가 나왔다.
delete 문을 실행해보았다.
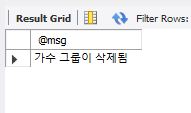
delete from trigger_table where id=4;
select @msg;
delete 문을 실행하니 트리거가 작동해 변수를 조회하니 설정한 내용을 출력되는 것을 확인할 수 있었다.
트리거 활용
트리거는 테이블에 입력 / 수정 / 삭제 되는 정보를 백업하는 용도로도 사용할 수 있다.
이때 테이블에 이벤트가 먼저 적용된 후 트리거가 실행된다.
이것을 확인하기 위해 member 테이블에 입력된 회원의 정보가 변경될때 변경한 데이터를 기록하는 트리거를 작성했다.
아래는 select문을 사용하여 데이터를 읽어와 그것을 새로운 테이블을 생성해 데이터를 넣어주도록 했다.
use market_db;
create table singer (select mem_id, mem_name, mem_number, addr from member);
백업테이블 생성
변경되기 전의 데이터를 저장할 백업 테이블을 생성했다.
백업 테이블에는 수정 또는 삭제인지 구분하는 modtype, 변경된 날짜(modedate) , 변경한 사용자(moduser)를 추가했다.
create table backup_singer
( mem_id char(8) not null,
mem_name varchar(10) not null,
mem_number int not null,
addr char(2) not null,
modtype char(2),
moddate date,
moduser varchar(30));
아래는 변경(update)이 발생했을때 작동하는 트리거를 만들었다.
drop trigger if exists singer_updatetrg;
delimiter $$
create trigger singer_updatetrg after update on singer for each row
begin
insert into backup_singer values(old.mem_id, old.mem_name, old.mem_number, old.addr, '수정', curdate(), current_user());
end $$
delimiter ;
아래는 삭제(delete)가 발생했을때 작동하는 트리거를 만들었다.
drop trigger if exists singer_deletetrg;
delimiter $$
create trigger singer_deletetrg after delete on singer for each row
begin
insert into backup_singer values(old.mem_id, old.mem_name, old.mem_number, old.addr, '삭제', curdate(), current_user());
end $$
delimiter ;
old 테이블을 볼 수 있다.
old테이블은 update delete가 수행될 때 변경되기 전의데이터가 잠깐 저장되는 임시 테이블이다.
old테이블에 update문이 작동되면 업데이트되기전의 데이터가 백업테이블에 입력되도록 작성했다.
아래의 쿼리문에서 수정 또는 삭제된 내용이 잘 보관되어 있는지 결과를 확인한다.
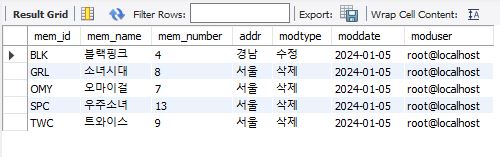
update singer set addr = '영국' where mem_id = 'BLK';
delete from singer where mem_number >= 7;
select * from backup_singer;
trunccate는 delete와 같은 효과를 낸다.
모든 행의 데이터를 삭제한다.
truncate table singer;
select * from backup_singer;

트리거가 사용하는 임시테이블
테이블에 insrt, update, delete 작업이 수업되면 임시로 사용되는 테이블 2개가 있다.
이것은 임시 사용을 하는 테이블이다.
두가지의 종류가 이름을 가지는데 첫번째는 new 두번째는 old가 있다.
이 테이블은 시스템 테이블이므로 자동으로 생성되어있다.
명령어별 작동을 설명하겠다.
insert
insert문 insert문은 삽입하는 기능을 한다.
바로 새값을 테이블에 삽입하는 것이 아닌 new 테이블에 잠깐 들어가져 있다.
그후 테이블로 이동해 값을 삽입한다.
(new는 많이 사용하지 않는다. 어차피 new 테이블에 들거간 값은 테이블에 들어가있음)
delete
delete문은 old테이블을 사용한다.
delete 문을 실행하면 삭제되기 전에 old테이블에 잠깐 들어가 있다.
그래서 트리거를 작성할 때 after delete트리거를 만들어 삭제된 후에 old.열 이름 형식으로 예전 값에 접근할 수 있다.
update
update문은 new, old 두개 다 사용한다.
update를 실행하면 new 테이블에 새값을 저장한 후 원래 테이블에 새 값을 삽입한다.
이 과정에서 예전의 값은 old 테이블로 저장되어진다.
'코딩 > SQL' 카테고리의 다른 글
| date_format (0) | 2024.04.04 |
|---|---|
| SQL 용어 정리 (1) (1) | 2024.01.07 |
| [13주 5일차] 인덱스 (0) | 2024.01.05 |
| [13주 4일차] 테이블과 뷰 (2) | 2024.01.04 |
| [13주 3일차] SQL 고급 문법 : 조인 (1) | 2024.01.03 |
- Total
- Today
- Yesterday