
티스토리 뷰
Chapter 03. SQL 기본 문법
create database market_db default character set utf8 collate utf8_bin;
use market_db;
member 테이블 작성
create table member(
mem_id varchar(8) not null primary key,
mem_name varchar(10) not null,
mem_number int not null,
addr varchar(2) not null,
phone1 varchar(3),
phone2 varchar(8),
height int,
debut_date date
);
ALTER TABLE member CHARSET=UTF8;
insert into member values('TWC','트와이스',9,'서울','02','11111111',167,'2015.10.19');
insert into member values('BLK','블랙핑크',4,'경남','055','22222222',163,'2016.08.08');
insert into member values('WMN','여자친구',6,'경기','031','33333333',166,'2015.01.15');
insert into member values('OMY','오마이걸',7,'서울','','',160,'2015.04.21');
insert into member values('GRL','소녀시대',8,'서울','02','44444444',168,'2007.08.02');
insert into member values('ITZ','잇지',5,'경남','','',167,'2019.02.12');
insert into member values('RED','레드벨벳',4,'경북','054','55555555',161,'2014.08.01');
insert into member values('APN','에이핑크',6,'경기','031','77777777',164,'2011.02.10');
insert into member values('SPC','우주소녀',13,'서울','02','88888888',162,'2016.02.25');
insert into member values('MMU','마마무',4,'전남','061','99999999',165,'2014.06.19');
update member set phone1=null, phone2=null where phone1='';
buy 테이블 작성
create table buy(
num int auto_increment not null primary key,
mem_id varchar(8) not null,
prod_name varchar(6) not null,
group_name varchar(4),
price int not null,
amount int not null,
foreign key (mem_id) references member(mem_id)
);
ALTER TABLE buy CHARSET=UTF8;
insert into buy values(1,'BLK','지갑','',30,2);
insert into buy values(2,'BLK','맥북프로','디지털',1000,1);
insert into buy values(3,'APN','아이폰','디지털',200,1);
insert into buy values(4,'MMU','아이폰','디지털',200,5);
insert into buy values(5,'BLK','청바지','패션',50,3);
insert into buy values(6,'MMU','에어팟','디지털',80,10);
insert into buy values(7,'GRL','혼공SQL','서적',15,5);
insert into buy values(8,'APN','혼공SQL','서적',15,2);
insert into buy values(9,'APN','청바지','패션',50,1);
insert into buy values(10,'MMU','지갑','',30,1);
insert into buy values(11,'APN','혼공SQL','서적',15,1);
insert into buy values(12,'MMU','지갑','',30,4);
03-1. select ~ from ~ where
select 문은 테이블에서 데이터를 추출하는 기능을 한다.
데이터를 변경하는 것이 아니라 단순히 추출하여 조회하는 기능을 한다.
기본적인 형식은 select ~ from ~ where 이다.
select 뒤에는 컬럼명, from 뒤에는 table 이름, where 뒤에는 조건식이 오는데 조건식은 행(row)을 정한다. (컬럼들 중 특정 행만 조회하는 것)
기본 조회하기 : select ~ from
- use
select 문을 실행하기 전에 앞서 어떤 데이터베이스를 사용할지 지정해야한다.
use 데이터베이스이름;
select 문의 기본 형식
select 컬럼명
from 테이블명
where 조건식
group by 컬럼명
having 조건식
order by 컬럼명
limit 숫자
이때 limit는 선착순으로 숫자만큼의 갯수만 출력한다.
위의 모든 것을 작성하는 것이 아니라 select를 제외하고는 생략이 가능하다.
select문에서 기본적으로 사용하는 형식은 다음과 같다.
select 컬럼명
from 테이블명
where 조건식
기본적인 조회 명령어를 사용하는 형식은 두가지가 존재한다.
아래의 두가지 select 문은 member테이블의 * (모든 데이터)를 조회하는 쿼리문이다.
조회결과는 같지만 작성 형식에 차이점이 있다.
첫번째 쿼리문은 from 뒤에 데이터베이스명이 생략되어 있다.
이유는 앞서 보았던 use 명령어를 사용하여 사용할 데이터베이스를 지정해주었기 때문에 작성하지 않아도 결과를 조회할 수 있다.
select * from member;
두번째 쿼리문은 첫번째와 다르게 데이터명.테이블명 과 같이 작성되어있다.
이와 같이 작성한 이유는 앞서 사용할 데이터베이스를 지정하지 않았을 경우 아래와 같이 작성한다.
사용할 데이터명을 작성해야만 원하는 테이블을 조회할 수 있기 때문이다.
select * from market_db.member;
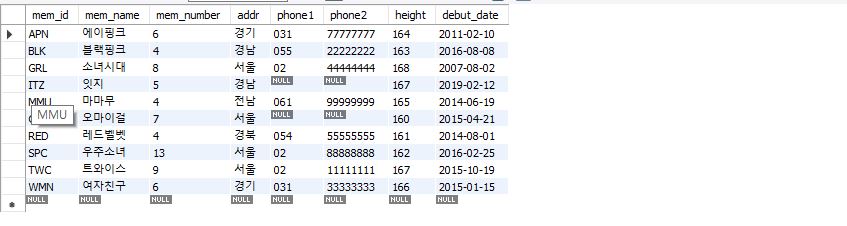
모든 데이터를 조회하는 것을 보았지만 그것이 아닌 특정 컬럼만을 조회를 할 수 있다.
특정 컬럼을 조회할 경우는 조회하고자하는 컬럼명을 select 뒤에 작성해주면 된다.
select mem_name from member;

* 컬럼 이름에 별칭을 지정할 수 있다. 열 이름을 작성한 후 지정하고 싶은 별칭을 입력하면 된다.
(만약 별칭에 공백이 있으면 큰따옴표로 묶어준다.)
select mem_name as "멤버 이름" from member;
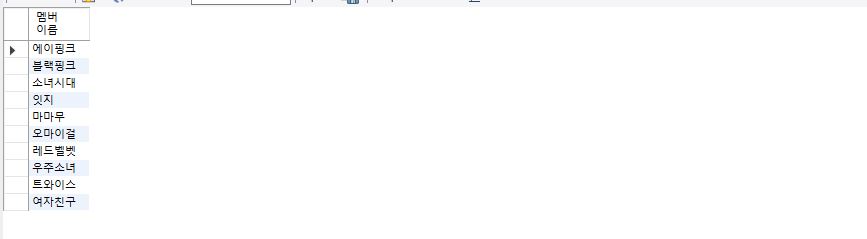
아래의 쿼리문과 같이 as를 여러개 작성할 수 있다.
select addr 주소, debut_date 데뷔일자, mem_name 멤버이름 from member;
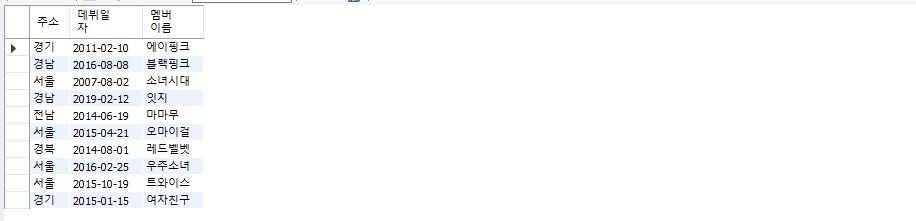
위와 같이 하나의 컬럼만 조회도 가능하지만 여러개의 특정 컬럼을 함께 조회할 수 도 있다.
여러개를 같이 조회할 경우 ,로 구분하여 컬럼명들을 작성해준다.
select addr, debut_date, mem_name from member;
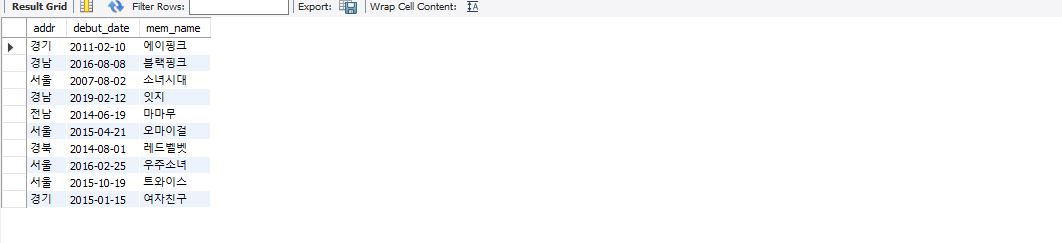
특정한 조건만 조회하기 : select ~ from ~ where
where 조건식이 없이도 컬럼을 조회를 할 수 있다.
하지만 조건식이 없다면 다량의 데이터를 조회할 경우 컴퓨터에도 부담이 되고 데이터를 찾는 것에 어려움이 발생한다.
그렇기 때문에 where 조건식을 사용한다.
기본적인 where 절
select 컬럼명 from 테이블명 where 조건식;
(세미콜론(;) 이 나오기 전까지는 한 줄로 쓰던지 여러 줄로 쓰던지 동일하게 한줄로 취급한다.)
찾는 데이터의 이름(mem_name)이 블랙핑크일 때는 where mem_name="블랙핑크"; 와 같이 조건식을 작성하여 데이터를 조회한다. 문자 데이터를 조회할 경우는 따옴표를 사용해야한다.
select * from member where mem_name='블랙핑크';

데이터의 인원(mem_number)과 같이 숫자 데이터를 조회할 경우는 따옴표를 사용하지 않아된다.
select * from member where mem_number=4;

관계 연산자, 논리 연산자의 사용
지금 우리가 다루는 데이터는 문자 혹은 숫자이다.
where 조건식에도 문자일 때 사용하는 방식과 숫자일때 사용하는 방식이 존재한다.
숫자로 표현된 데이터 범위 지정
관계 연산자(>,<,>=,<=,= 등)와 논리 연산자(and, or)를 사용하여 조회할 수 있다.
관계 연산자를 사용하여 height의 데이터가 162보다 작거나 같은 mem_id, mem_name 쿼리를 조회하는 쿼리문
select mem_id, mem_name from member where height<=162;

관계 연산자와 논리 연산자를 사용하여 height의 데이터가 165보다 크거나 같거나 mem_number이 6보다 큰 mem_id, mem_name 쿼리를 조회하는 쿼리문
select mem_name, height, mem_number from member where height>=165 or mem_number>6;

between ~ and
and 연산자를 사용하여 조건식에 해당하는 값들만 조회할 수 있다.
앞서 학습한 관계 연산자와 논리 연산자를 사용하여 쿼리문을 구성할 수 있다.
하지만 between ~ and를 사용하여 쿼리문을 좀 더 간단히 할 수 있다.
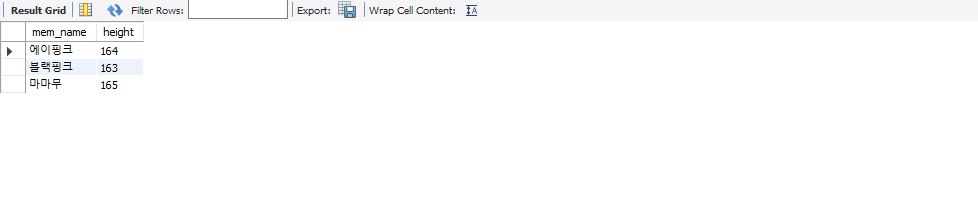
select mem_name, height from member where height >=163 and height <=165;
163과 165 사이의 범위에 있는 값을 구하는 경우 아래와 같이 between ~ and을 사용할 수 있다.
위의 쿼리문과 아래의 쿼리문은 같이 조회 결과를 나타낸다.
select mem_name, height from member where height between 163 and 165;
문자로 표현된 데이터 범위 지정
in()
숫자로 구성된 데이터는 크다/작다와 같은 범위를 지정할 수 있지만 문자로 구성된 데이터는 범위를 지정할 수 없다.
그렇기 때문에 경남 / 전남 / 경남 중 한 곳에 사는 회원을 조회하고자하는 경우 아래와 같이 논리 연산자(or)을 사용하여 하나 하나 작성해주어야 한다.
select mem_name, addr from member where addr='경기' or addr='전남' or addr='경남';
하지만 in() 을 사용하면 코드를 간단하게 작성할 수 있다.
select mem_name, addr from member where addr in('경기','전남','경남');
조회 결과를 살펴보면 아래와 같은 결과를 두 쿼리문이 동일하게 출력하는 것을 볼 수 있다.

like
문자열의 일부 글자를 검색하고자하려면 like를 사용한다.
그러려면 글자 조건을 작성해야하는데
표현법은 두가지가 있다.
첫번째는 % 이다.
%은 글자수에 상관 없이 포함하는 문자를 이야기한다.
예를 들어 '우'로 시작하는 회원을 검색하려면 '우%'로 표현할 수 있다.
이러한 표현법을 사용하면 우로 시작하지만 글자수에 상관 없이 조회할 수 있다.
select * from member where mem_name like '우%';
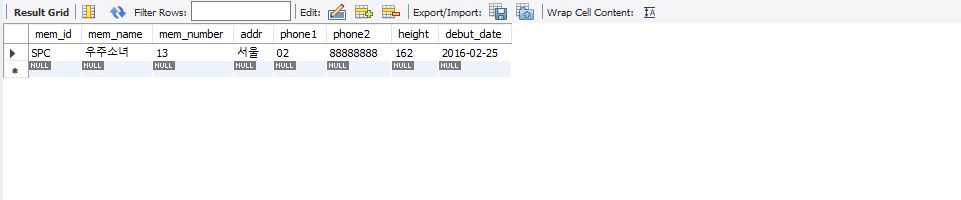
* '%우%' : '우'가 포함되는 글자는 모두 조회할 수 있다.
'%.jpg' : 확장자명이 .jpg인 것을 조회할 수 있다.
두번째는 _(언더바)이다.
_ 는 글자수 제한이 있다.
_하나는 한글자를 뜻하므로 '우_'로 작성되었다면 우로 시작하는 두글자 단어를 조회할 수 있다.
만약 핑크로 끝나는 네글자를 조회하고자 하면 '__핑크' 와 같이 작성되어야한다.
select * from member where mem_name like '__핑크';

서브 쿼리
select 안에는 또 다른 select문이 들어갈 수 있다. (즉, 쿼리를 두번 실행하는 것과 같음)
이것을 서브 쿼리 또는 하위 쿼리라고 한다.
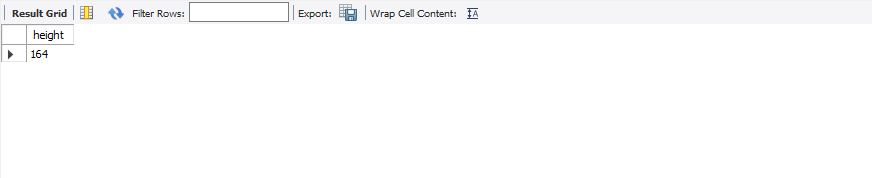
에이핑크라는 그룹이름의 평균 키를 조회했다.
-- 서브쿼리문
select height from member where mem_name='에이핑크'; -- 결과값 164
결과는 164라는 값이 나왔다.
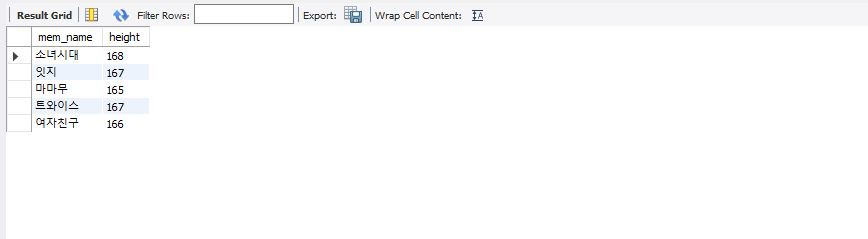
에이핑크의 평균키인 164를 초과하는 평균 키를 가진 그룹의 이름과 평균 키를 조회하고자 했다.
서브쿼리를 모르는 상태인 지금 아래와 같은 쿼리문을 실행하는 방법으로 조회를 할 수 있다.
하지만 아래와 같은 방법은 키가 정확히 어떠한 데이터를 가지고 있는지 아는 상태에서만 작성이 가능하다.
select mem_name, height from member where height>164;
그러한 단점을 극복하기 위해 서브쿼리문을 사용한다.
괄호 안의 select문을 먼저 실행하여 평균 키를 구한 후 height의 값 범위를 구해주고 나머지 select문을 실행한다.
select mem_name, height from member where height > (select height from member where mem_name='에이핑크');
03-2. 좀 더 깊게 알아보는 select 문
select 문에서는 정렬이 가능하다.
정렬을 하는 경우 order by, limit, distinct 등을 사용할 수 있다.
group by는 지정한 열의 데이터들을 같은 데이터끼리 묶어 결과를 추출한다.
group by 사용하는 경우 합계, 평균, 개수 등을 처리하는 경우가 많으므로 집계 함수와 함께 사용된다.
또한, group by는 where과 사용을 할 수 없다. 그러므로 비슷한 having과 사용된다.
order by 절
order by 절은 결의 값이나 개수에 영향을 미치는 것이 아닌 출력되는 순서를 조절 즉 정렬을 한다.
select mem_id, mem_name, debut_date from member order by debut_date;
debut_date를 기준으로 정렬하므로 아래와 같은 결과가 나온다.
order by를 사용하는 경우 desc와 asc를 사용할 수 있는데 desc는 내림차순 (5 4 3 2 1) 을 의미하고 asc는 오름차순 (1 2 3 4 5) 을 의미한다. order by 뒤에 아무것도 작성하지 않은 경우 기본값은 asc이다.

select mem_id, mem_name, debut_date from member order by debut_date desc; -- desc 내림차순
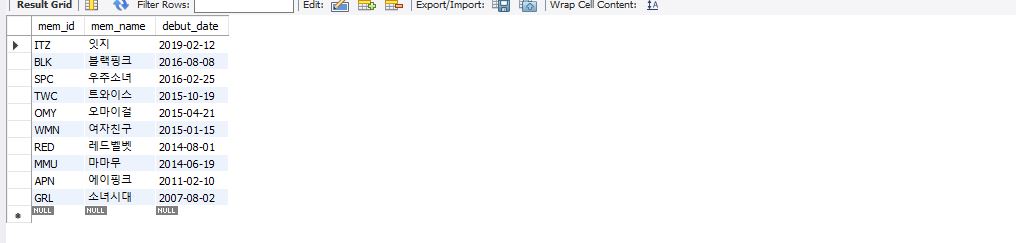
또한, order by 절은 where 절과 함께 사용할 수 있다.
하지만 작성 순서에 유의해야한다.
where 절이 먼저 위치한 후 order by 절이 작성 되어야 한다.
where 절은 조건식이므로 조건에 만족하는 값들을 가져온 후 order by로 마지막 정렬을 해주어야하기 때문이다.
select mem_id, mem_name, debut_date, height from member where height >= 164 order by height desc;
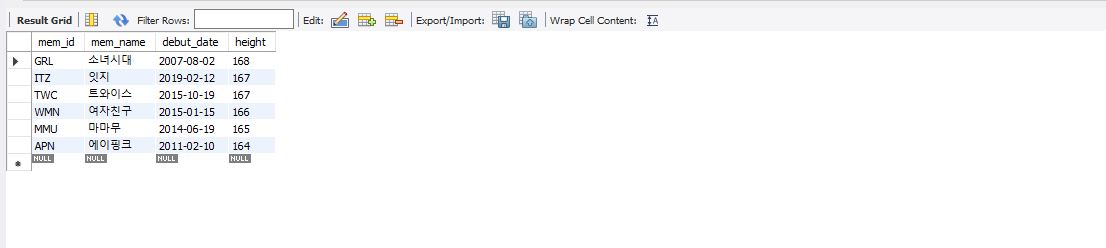
위의 결과를 살펴보면 잇지와 트와이스의 평균 키가 동일하다.
하지만 트와이스가 debut_date가 더 빠르므로 키가 동일할 경우 데뷔 일자로 먼저 정렬되도록 쿼리문을 작성할 수 있다.
select mem_id, mem_name, debut_date, height from member where height >= 164 order by height desc, debut_date asc;
height로 desc 정렬한 후, 동일 값이 있으면 debut_date로 asc 정렬하도록 작성해주었다.
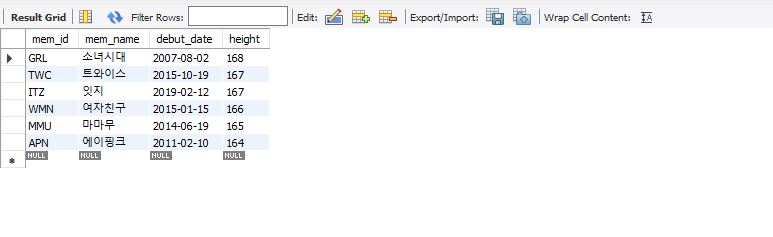
위의 결과를 보면 트와이스가 먼저 정렬된 것을 볼 수 있다.
출력 개수를 제한 : limit
limit은 출력하는 개수를 제한한다.
출력 값들을 정렬한 후 마지막으로 작성해주는데 limit 뒤에 오는 숫자만큼만 조회할 수 있도록 한다.
select mem_name, debut_date from member order by debut_date limit 3;
limit 3 과 같이 작성했을 경우 첫 시작은 0으로 본다.
즉, 맨처음 값부터 3번째 값까지를 출력한다.
select mem_name, height from member order by height desc limit 3,2; -- 시작지점 지정함 3번째부터 2개 조회
limit 3,2 와 같이 작성되었을 경우 첫번째로 오는 숫자는 start 숫자 마지막 숫자는 조회할 갯수를 뜻한다.
시작 지점은 3이므로 3부터 2개의 데이터를 조회할 수 있다.
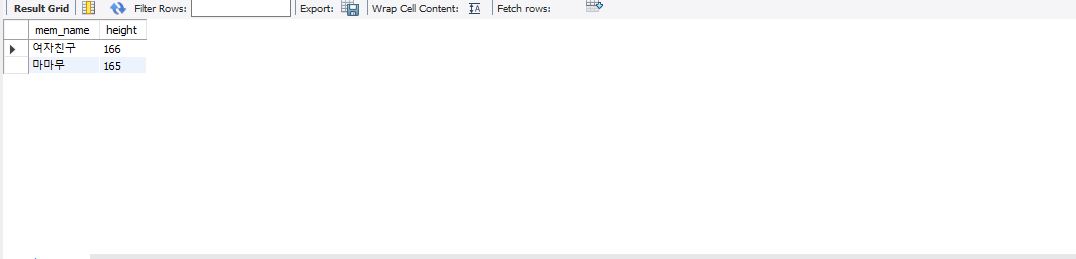
중복된 결과를 제거 : distinct
disticnt 는 조회된 결과에서 중복된 데이터를 제거하고 1개만 남긴다.
select addr from member;
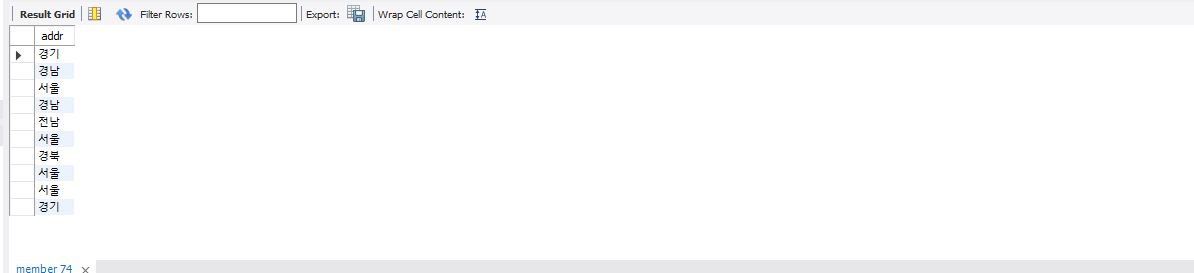
distinct를 사용하지 않을 경우 많은 중복되는 데이터들 때문에 파악하기 어렵다는 단점이 있다.
그러므로 distinct를 사용하여 중복을 제거해준다.
select distinct addr from member;
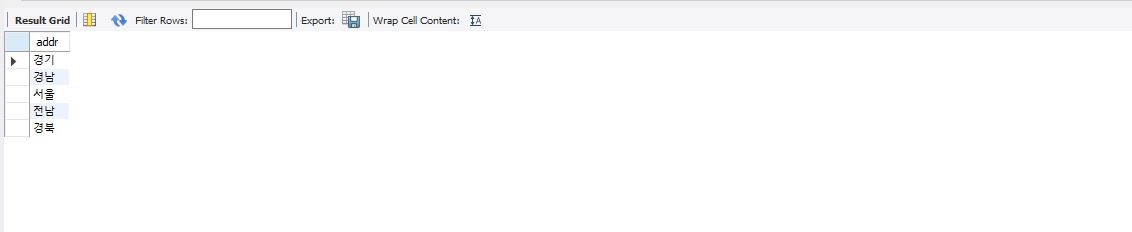
distinct를 사용할 경우 위의 조회결과와 같이 중복된 값을 제거하는 것을 볼 수 있다.
group by 절
group by 절은 그룹으로 묶어주는 역할을 한다.
얼핏 보면 distinct와 비슷해 보일 수 있으나 집계 함수를 사용하여 그룹별로 값을 도출할 수 있다.
select mem_id, amount from buy order by mem_id;
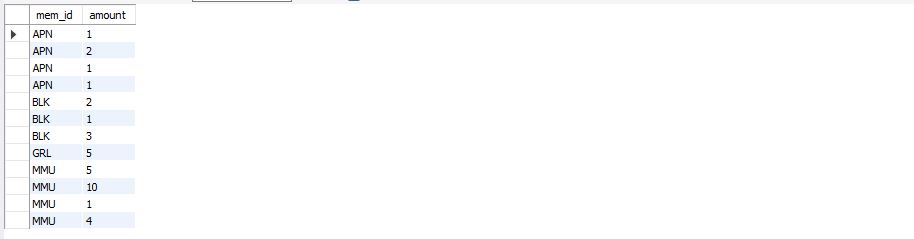
mem_id와 amount의 총 합계를 조회하고 mem_id를 기준으로 정렬한다.
select mem_id, sum(amount) from buy group by mem_id;
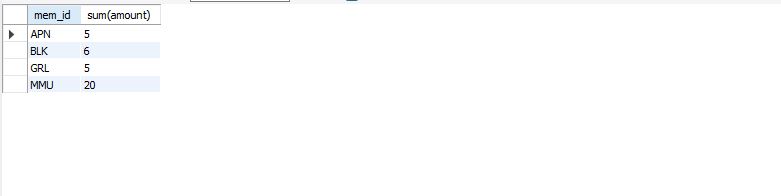
집계 함수
group by 절과 함께 주로 사용된다.
| 함수명 | 설명 |
| sum() | 합계를 구한다. |
| avg() | 평균을 구한다. |
| min() | 최소값을 구한다. |
| max() | 최대값을 구한다. |
| count() | 행의 개수를 센다. |
| count(distinct) | 행의 개수를 센다 (중복은 제거 (1개만 인정)) |
group by로 mem_id 그룹끼리 묶은 후 amount를 sum하여 그룹별로 amount를 합한 값을 조회했다.
select mem_id, sum(amount) from buy group by mem_id;
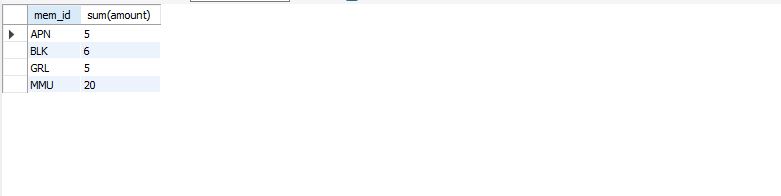
as를 이용하여 별칭을 작성하고 prices*amount를 계산하고 mem_id로 그룹끼리 묶었다.
select mem_id "회원 아이디", sum(price*amount) "총 구매 금액" from buy group by mem_id;

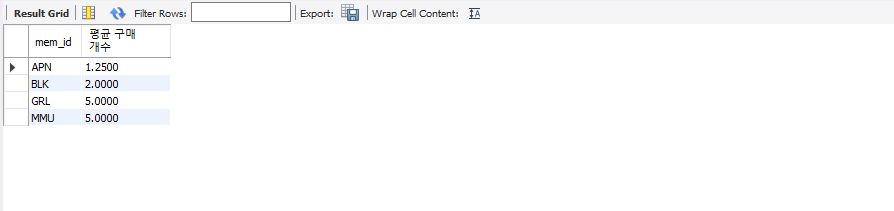
이전에서는 sum 집계함수만 사용했지만 avg를 사용하여 amount의 평균을 구한다.
select mem_id, avg(amount) "평균 구매 개수" from buy group by mem_id;
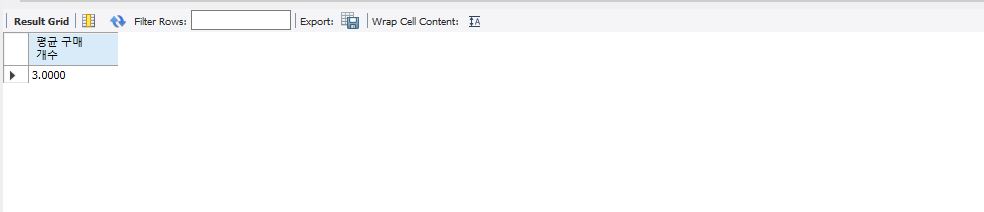
전체의 amount의 평균을 구하는 쿼리문
select avg(amount) "평균 구매 개수" from buy;
member 테이블의 모든열을 count하는 쿼리문이다.
이때는 null값도 포함하여 count한다.
select count(*) from member;

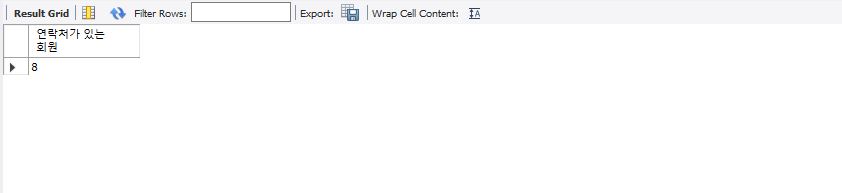
member 테이블의 phone1 칼럼의 갯수를 조회하는 쿼리문이다.
이러한 형식의 쿼리문은 null 값은 포함하지 않고 count한다.
select count(phone1) "연락처가 있는 회원" from member;
having 절
having 절은 where 절과 같다.
group by절과 함께 사용하는데 group by 절을 사용할 때는 where 절을 사용할 수 없으므로 조건식을 작성하고자할때 having과 함께 사용한다.
mem_id는 as 회원 아이디라고 하고, sum(price*amoun)를 조회한다.
테이블은 buy 테이블이고 mem_id를 기준으로 하여 그룹해 묶는다.
select mem_id "회원 아이디", sum(price*amount) "총 구매 금액" from buy group by mem_id;
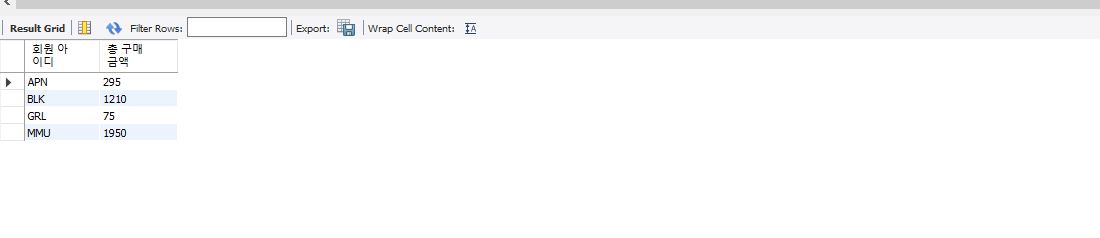
group by mem_id를 기준으로 묶고 mem_id와 sum 값을 조회한다. 그리고 sum 값이 1000보다 큰 값들만 조회한다.
select mem_id "회원 아이디", sum(price*amount) "총 구매 금액" from buy group by mem_id having sum(price*amount) >1000;
위와 같은 조건을 조회하면 다음과 같은 결과를 볼 수 있다.
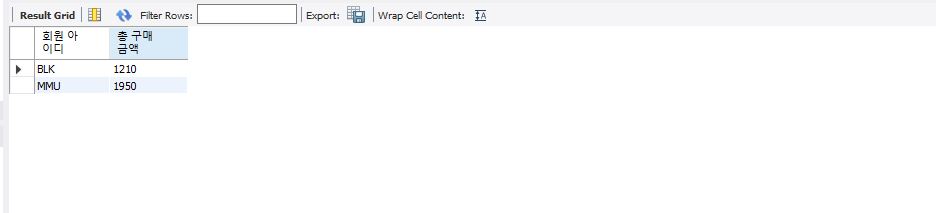
위의 쿼리문과 일치해보이지만 차이점이 존재한다.
having 뒤에 order by 절이 존재한다.
이러한 경우에는 정렬을 도와주는데 sum(price*amount) desc 이므로 내림차순으로 정렬한다.
select mem_id "회원 아이디", sum(price*amount) "총 구매 금액" from buy group by mem_id having sum(price*amount) > 1000 order by sum(price*amount) desc;
dsec하여 정렬하면 큰수에서 작은 수로 내림차순되어 정렬되는 것을 볼 수 있다.

'코딩 > SQL' 카테고리의 다른 글
| [13주 3일차] SQL 고급 문법 : 조인 (1) | 2024.01.03 |
|---|---|
| [13주 3일차] SQL 기본 문법 (1) | 2024.01.03 |
| [13주 3일차] SQL 고급 문법 (1) | 2024.01.03 |
| NULL관련 함수(NVL, NULLIF, COALESCE) (0) | 2023.10.29 |
| SQLD 노랭이 87번 문제(p.94) /다시 업로드 예정/ (0) | 2023.10.29 |
- Total
- Today
- Yesterday